ML: Clasificador de Religión de Países
Para este proyecto cree un clasificador que busca identificar correctamente la religión de un país dada su ubicación geográfica, su área en kilometros cuadrados, su población en millones de personas, su idioma y las características de su bandera, como lo son su color y las formas que contiene: circulos, cruces, estrellas, medias lunas, triangulos, etc… Para este proposito, utilice el set de datos de banderas del repositorio de Machine Learning de la Universidad de California Irvine el cual, contiene información de 194 países.
A lo largo del proyecto se encuentra:
- Limpieza de datos y estandarización.
- Estadística descriptiva en los predictores para identificar outliers en los datos.
- Selección de los predictores más influyentes para identificar correctamente la religión de un país.
- Creación de Pipelines para testear diferentes tipos de clasificadores y así, poder encontrar el mejor modelo.
Y ⟶ Output
La variable objetivo (Y) es la religión de un país y se encuentra categorizada de la siguiente manera:
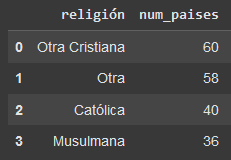
Tabla 1: Variable Objectivo
Como se puede observar, los países analizados se clasifican en 4 religiones. 60 países (30.92%) tienen como religión Other Christian (Ortodoxos, Anglicanos, Evangélicos) mientras que, 58 países (29.89%) son clasisficado en la categoria de otra (Other) religión. Por otro lado, 40 países (20.61%) son católicos mientras que, los restantes 36 países (18.55%) son musulmanes.
X ⟶ Predictores
Ahora bien, los predictores númericos se encuentran en diferentes escalas por lo que, es necesario transformarlos con un MinMaxScaler para que su rango de valores se encuentre entre [0, 1]. A esto se le suma, que hay una gran cantidad de outliers en los predictores sunstars, population y area que pueden afectar el desempeño del modelo. Debido a esto, se utilizó el transformador Winsorizer el cual usa cuantiles y un pliegue (fold) = 0.5 para limitar los valores dentro del rango del 5to al 95avo percentil. La figura que se muestra a continuación, muestra las variables númericas después de la transformación con el Winsorizer.
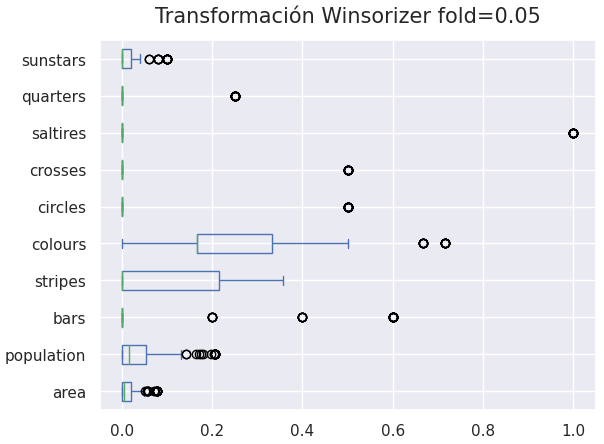
Figura 1: Transformación Winsorizer fold = 0.05
Pasando a las variables categóricas (mainhue, topleft y botright), un transformador One Hot Encoder fue utilizado para mapear las categorias a números. La figura 2 muestra el Pipeline creado para transformar y estandarizar los predictores y entrenar un Árbol de Decisión para determinar las variables más influyentes del clasificador.
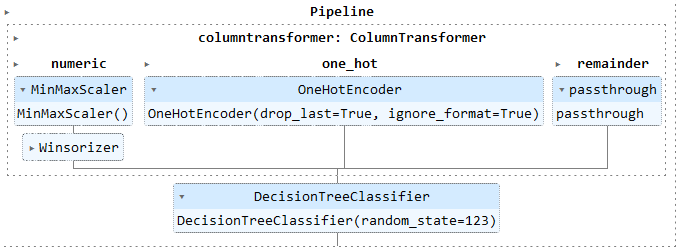
Figura 2: Pipeline de Transformación
Después de ejecutar el Pipeline, los predictores más influyentes para correctamente clasificar las religión de un país se muestran a continuación.
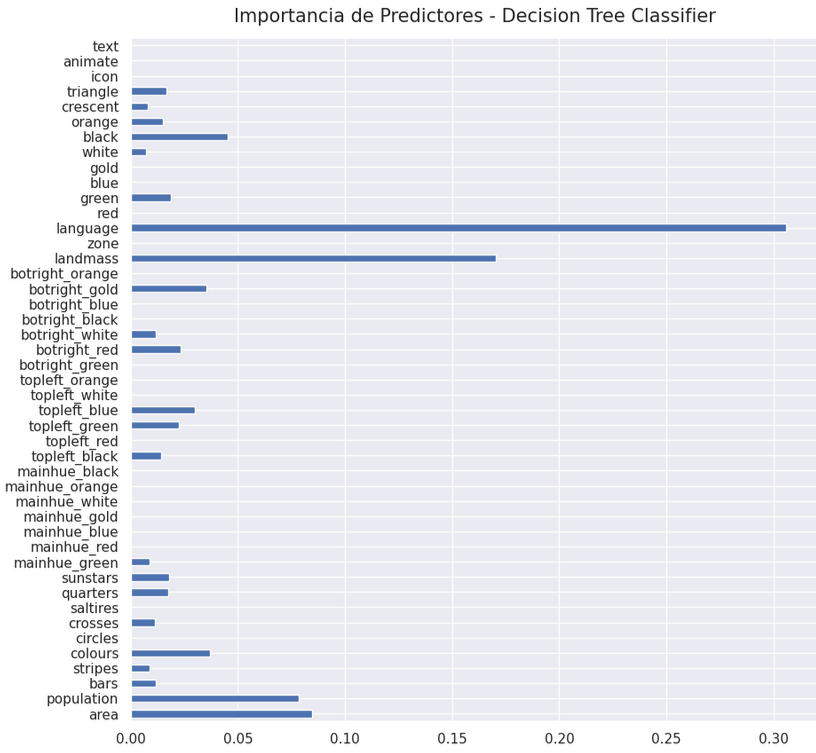
Figura 3: Importancia de Predictores - Árbol de Decisión
Selección del Modelo
Se creo un Pipeline para testear 3 diferentes tipos de clasificadores (Árbol de Decisión, Random Forest y XGBoost) y así poder determinar el modelo que tiene el mejor desempeño en clasificar la religón de páises nuevos. Los 3 modelos fueron probados con diferentes valores en sus hiperparámetros y con una validación cruzada de 5 pliegues, para reducir el riesgo de sobreajuste. A continuación, se puede observar la grilla de hiperparámetros que fue usada.
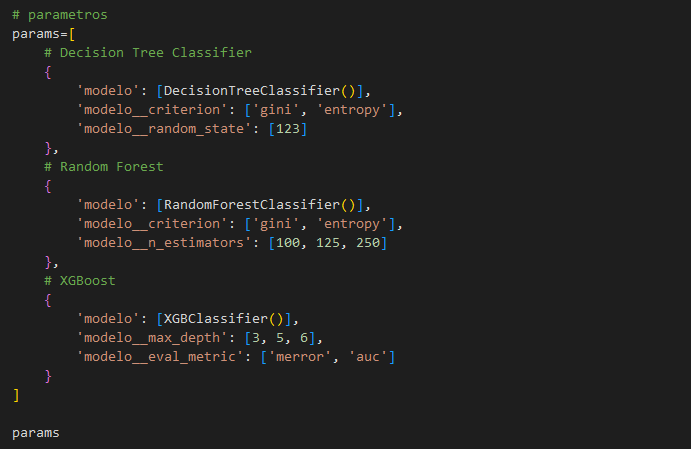
Figure 4: Grila de Hiperparámetros
De esta manera, después del entrenamiento y prueba de cada posible combinación de cada uno de los modelos, el mejor modelo fue un Random Forest Classifier con los siguientes hiperparámetros:
- criterion: entropy
- n_estimators: 100
Desempeño del Mejor Modelo
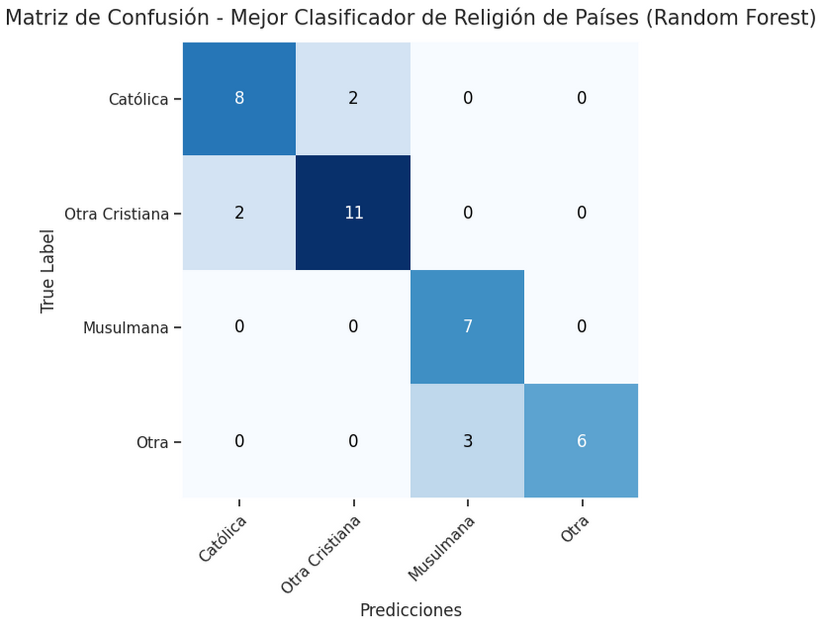
Como se enunció en el apartado anterior, el modelo que tiene el mejor desempeño en clasificar la religión de países nuevos fue un Random Forest Classifier el cual obtuvo las siguientes métricas:
- Accuracy: 0.82
- F1-Score weighted average: 0.82
- Precision weighted average: 0.84
- Recall weighted average: 0.82
El menor valor de Recall fue de 0.67 en la categoria de otra religión (Other). Esto muestra que el clasificador tiene una tendencia a no clasficar países en la categoría de otra religión cuando efectivamente lo son. Por otro lado, el menor valor de Precision fue de 0.7 en la religión musulmana. Esto quiere decir, que el modelo tiene una tendencia a clasificar países como musulmanes cuando en realidad no lo son. A continuación, se puede observar la Matriz de Confusión del mejor modelo.