NLP: Recomendador de Películas TF-IDF
Para este proyecto cree una aplicación web en python que utiliza un modelo TF-IDF de los generos y las palabras clave de las películas y la similitud de coseno, la cual mide la semejanza entre dos vectores, para recomendarle cinco películas al usuario, dado una película que le haya gustado. Se utilizó un set de datos de TMDB (The Movie Database) que contiene 5000 filmes, con sus respectivos generos y palabras clave, entre el año 1916 al 2017.
A lo largo del proyecto se encuentra:
- Limpieza de datos y estandarización.
- Creación de las matrices de vocabulario y de frecuencia de termino.
- Modelo TF-IDF.
- Similitud de Coseno entre películas.
- Aplicación web.
Modelo TF-IDF
Generos y Palabras Clave de cada Película
Las columnas de genero (genres) y palabras clave (keywords) se encuentran en formato JSON por lo que es necesario extraer los valores y convertirlos a tipo string. Esto se hizo creando una función que recibe como parametro una película y convierte sus generos y palabras clave de JSON a una lista de diccionarios. Ahora bien, con un ciclo for cada genero y palabra clave son extraidos y concatenados a un string. La función regresa los generos y palabras clave de una película en una sola cadena de texto.
El siguiente paso es mapear cada genero y palabra clave único para crear la Matriz de Frecuencia de Termino. Los Tokens van a ser los generos y palabras clave únicos (V: 9769) mientras que el Corpus, es el número de películas en el set de datos que se estan analizando (N: 4777). De esta manera, la Matriz de Frecuencia de Termino tiene dimensiones (N, V) donde cada fila representa una película y las columnas con valores mayores a 0 representan un genero o palabra clave de la película.
Creación del Modelo TF-IDF
El modelo TF-IDF creado es un algoritmo que detecta que generos y palabras clave en el set de datos son las más importantes, al mismo tiempo que reduce la relevancia de los generos y palabras clave que constantemente se repiten entre las películas. Uilizando la Matriz de Frecuencia de Termino construida previamente, se puede calcular el número de veces que un genero o palabra clave aparece en una película.
Por otro lado, la Frecuencia Inversa del Documento (IDF) es el número de películas en las que un determinado genero o palabra clave aparece y este puede ser calculado de la siguiente manera:

Ecuación 1: Frecuencia Inversa del Documento
Donde:
- N: Número de películas en el set de datos
- Frecuencia de Documento: Vector que tiene el tamaño del vocabulario y muestra el número de películas en las que un genero y palabra clave aparece.
- Log: El logaritmo disminuye el efecto que tienen generos y palabras clave inusuales.
Similitud de Coseno
La similitud de coseno es una medida de similitud entre dos vectores diferentes de cero. Cuando dos vectores son similares, se encuentran cercanos entre sí y van a tener un valor cercano a 1. En este sentido, entre mayor sea la similitud de coseno entre dos películas estas van a ser más similares ya que, comparten generos y temáticas y por ende, se le puede recomendar al usuario. A continuación, se puede ver el gráfico de la similitud de coseno para la película de Mortal Kombat.
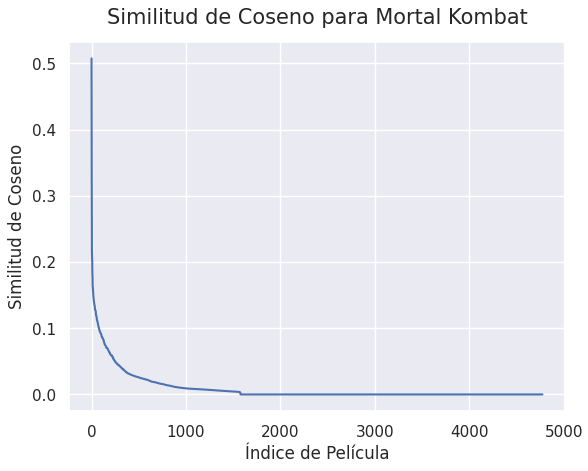
Figura 1: Similitud de Coseno para Mortal Kombat
Como se puede apreciar, hay aproximadamente 150 películas con una similitud de coseno mayor a 0.1 para esta film.
Aplicación Web
La aplicación web creada toma como input una película favorita del usuario y le recomienda 5 películas para ver con el puntaje de similitud de coseno más alto, basado en la premisa que comparten generos y temáticas que el usuario disfruta.
- Backend: Flask
- Frontend: HTML and CSS
- Hosting y Deployment: pythonanywhere.com
- Web App URL: http://princekike27.pythonanywhere.com/
