ML: Country Religion Classifier
For this project I created a classifier to correctly identify the religion of a country given its geographical location, its area in square kilometers, its population in millions of people, its language and the characteristics of its flag such as its color and the shapes that appear on it, like: circles, crosses, sunstars, crescents, saltires, triangles, etc… For this task, I used the flags dataset from the repository of Machine Learning of the University of California Irvine which contains information of 194 countries.
Throughout the project you will be able to find:
- Data cleaning and standardization.
- Descriptive Statistics on predictors to identify outliers.
- Selection of the most influential predictors for correctly classifying a country’s religion.
- Creation of Pipelines to test different classification models and find the best classifier.
Y ⟶ Output
The target variable (Y) is the religion of a given country and is categorized as its shown below:
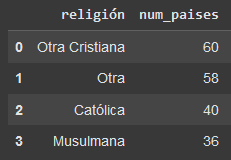
Table 1: Target Variable
As it can be seen, the countries analyzed are classified in 4 religions. 60 countries (30.92%) have as religion Other Cristian (Orthodox, Anglican, Evangelic) while 58 countries (29.89%) are classified on the Other religion category. On the other hand, 40 countries (20.61%) have Catholic as their primary religion while the remaining 36 countries (18.55%) are Muslim.
X ⟶ Predictors
The numeric predictors are in different scales hence, a MinMaxScaler was applied to all numeric features to transform them to a range of values of [0, 1]. On top of that, there are a lot outliers on the sunstars, population and area predictors which can affect the performance of the model. A Winsorizer transformer was used with quantiles and a fold=0.5 to limit their values to the 5th and 95th percentile. The figure shown below shows the numerical variables after the Winsorizer transformation.
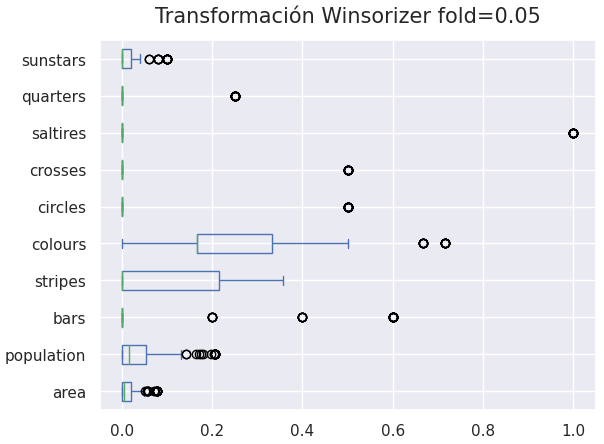
Figure 1: Winsorizer Transformation fold = 0.05
Moving forward to the categorical variables (mainhue, topleft and botright), a One Hot Encoder transformer was used to map the categories into numbers. Figure 2 shows the pipeline created to transform and standardize the predictors and to train a Decision Tree Classifier.
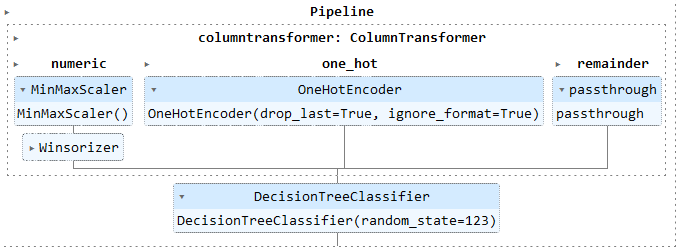
Figure 2: Transformation Pipeline
After running the Pipeline, the most influential predictors for correctly classifying a country’s religion can be seen below.
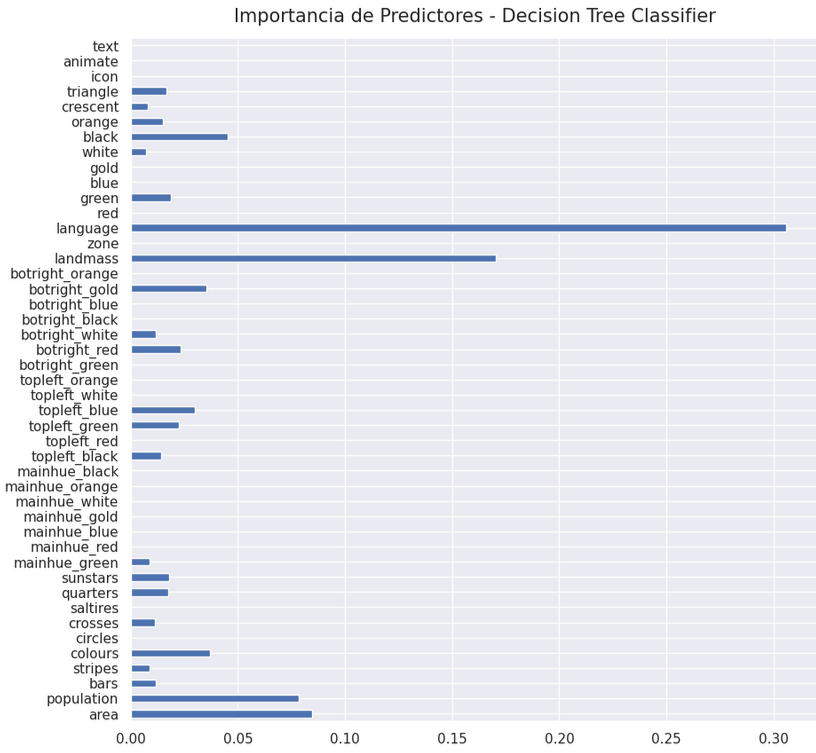
Figure 3: Predictor's Importance - Decision Tree Classifier
Model Selection
A pipeline was created to test 3 different types of classifiers (Decision Tree, Random Forest and XGBoost) in order to determine the model that has the best performance on classifying the religion of new countries. All 3 models were tested with different hyperparameter values and with 5-fold cross validation to reduce the risk of overfitting. Below we can see the hyperparameter grid that was used during this step.
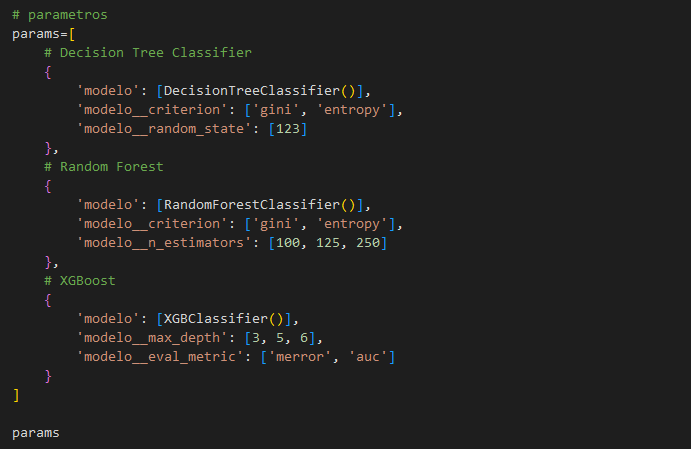
Figure 4: Hyperparameter Grid
After performing the training and testing of each model combination, the best model was the Random Forest Classifier with the following hyperparameters:
- criterion: entropy
- n_estimators: 100
Best Model Performance
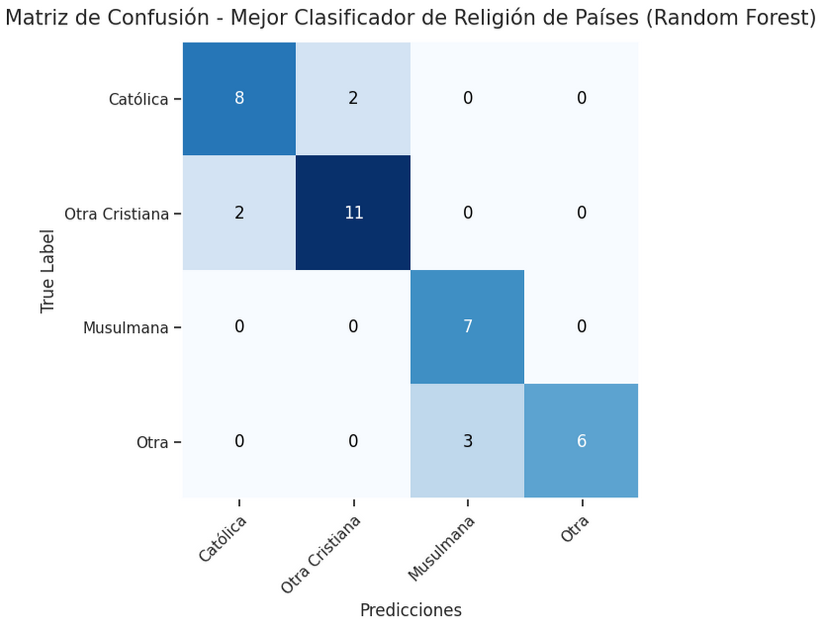
As it has been stated above, the model that has the best performance of classifying the religion of new countries is the Random Forest Classifier with obtained the following metrics:
- Accuracy: 0.82
- F1-Score weighted average: 0.82
- Precision weighted average: 0.84
- Recall weighted average: 0.82
As a side note, the lowest value of Recall was 0.67 on the Other religion category. This means that the classifier has a tendency of not classifying countries in the Other religion category when they are. On the other hand, the lowest value for Precision was 0.70 on the Muslim religion. This shows that the model has a tendency of classifying countries as Muslim when they aren’t. Below we can see the Confusion Matrix of the best model.