NLP: TF-IDF Movie Recommender
For this project I created a python Web App that uses a TF-IDF model of the genres and keywords of movies and cosine similarity, that measures the similarity between two non-zero vectors, to recommend five movies to the user, given a movie the user likes. For this task, I used a dataset from TMDB (The Movie Database) that contains 5000 movies, with their respective genres and keywords, between the year 1916 to 2017.
Throughout the project you will be able to find:
- Data cleaning and standardization.
- Creation of Vocabulary and Term-Frequency Matrices.
- TF-IDF Model.
- Cosine Similarity between Movies.
- Web Application.
TF-IDF Model
Genres and Keywords of each Movie
The genres and keywords columns are in JSON format hence, the values of each of these columns need to be extracted and stored in a string. By creating a custom function that receives as a parameter a movie, it turns its genres and keywords from JSON to a dictionary list. By using a for loop each genre and keyword is extracted and concatenated to a string. The function returns the genres and keywords of a movie in a single string.
The next step is to map each unique genre and keyword to create a Term-Frequency Matrix. The Tokens will be the unique genres or keywords (V: 9767) while the Corpus, the number of movies in the dataset being analyzed (N: 4777). In that sense, the Term-Freqency Matrix will have dimensions (N, V) where each row represents a movie and the columns with a value greater than 0 represent a genre or keyword of the movie.
Creation of TF-IDF Model
The created TF-IDF model is an algorithm that detects which genres and keywords in the dataset are the most important while at the same time, reducing the relevance of genres and keywords that constantly repeat among movies. By using the Term-Frequency Matrix built, we can calculate the number of times that a genre or keyword appears on a movie.
On the other hand, the Inverse Document Frequency is the number of movies in which a given genre or keyword appears and can be calculated in the following way:

Equation 1: Inverse Document Frequency
Where:
- N: Number of movies in the dataset.
- Document Frequency: Vector that has the size of the vocabulary and shows in how many movies a given genre or keyword appears.
- Log: The logarithm allows us to diminish the effect that unusual genres or keywords have.
Cosine Similarity
Cosine Similarity is a measure of similarity between two non-zero vectors. When two vectors are similar, they are close to each other and have a value closer to 1. In that sense, the higher the cosine similarity between two movies the more similar they will be because they share genres and themes and hence, they can be recommended to the user. Below we can see the cosine similarity graph for the Mortal Kombat movie.
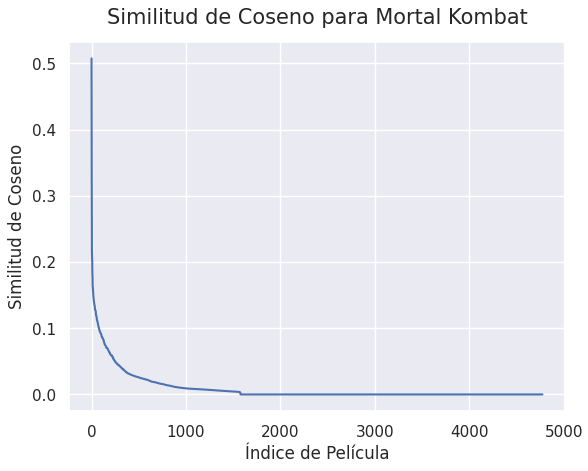
Figure 1: Cosine Similarity for Mortal Kombat
As it can be seen above, there are approximately 150 movies with a cosine similarity greater than 0.1 for this motion picture.
Web Application
The Web App that was created takes as input a movie the user likes and will recommend him 5 movies, with the highest cosine similarity scores, to watch, based on the premise that they share genres and themes that the user enjoys.
- Backend: Flask
- Frontend: HTML and CSS
- Hosting and Deployment: pythonanywhere.com
- Web App URL: http://princekike27.pythonanywhere.com/
